深度學習開始-在Pycharm中安裝函式庫
在開始深度學習之前,先將會用到的函示庫裝好,
照以下步驟:
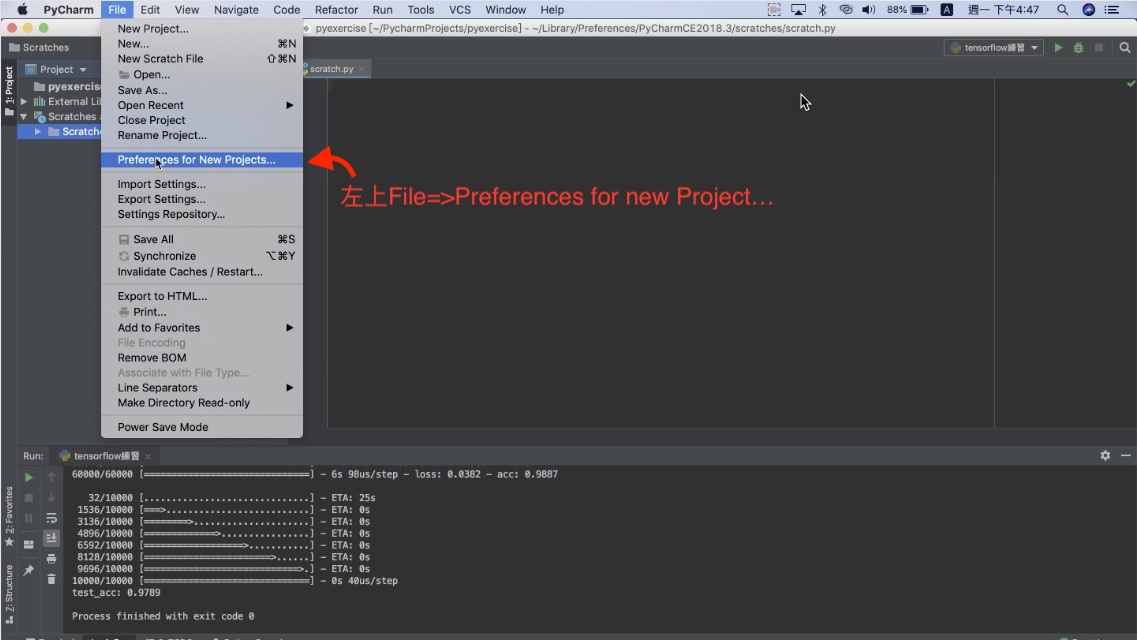

輸入需要新增的函示庫名稱,即可自動搜尋並且直接安裝。

預計之後會用到函式庫清單,可以一併先安裝起來:
1. numpy
2. BLAS
3. openBLAS
4. matplotlib
5. SciPy
6. Pydot-ng
7. tensorflow
8. theano
9. Keras










import re
fp = open("/Users/lido/Library/Preferences/PyCharmCE2018.3/scratches/sample.txt","r")
article = fp.read()
new_article = re.sub("[^a-zA-Z\s]","",article)
words = new_article.split()
for word in words: if word.upper() in word_counts: word_counts[word.upper()] = word_counts[word.upper()] +1 else: word_counts[word.upper()] = 1 key_list = list(word_counts.keys()) key_list.sort() for key in key_list: if word_counts[key] > 1: print("{}:{}".format(key,word_counts[key]),end=" ")
import re fp = open("/Users/lido/Library/Preferences/PyCharmCE2018.3/scratches/sample.txt","r") article = fp.read() new_article = re.sub("[^a-zA-Z\s]","",article) words = new_article.split() word_counts={} for word in words: if word.upper() in word_counts: word_counts[word.upper()] = word_counts[word.upper()] +1 else: word_counts[word.upper()] = 1 key_list = list(word_counts.keys()) key_list.sort() for key in key_list: if word_counts[key] > 1: print("{}:{}".format(key,word_counts[key]),end=" ")


















